I spend my days helping companies get real value from AI across the entire software development lifecycle—not just coding, but requirements, architecture, testing, and review. To keep my skills sharp, I use my spare time to see how far I can push this technology.
These are the projects that came out of that work. Each one taught me something different about where AI works, where it breaks, and what discipline it takes to close the gap. The methodology that emerged became PAAD , a Claude Code plugin that encodes what I’ve learned. More projects will appear here over time.
Tramp Freighter Blues
A browser-based space trading game where you captain a struggling freighter across 117 real star systems, trading cargo, dodging pirates, and managing a ship that’s slowly falling apart. Built with React, Three.js, and TypeScript—roughly 30,000 lines of code backed by over 2,300 tests.
This was my proving ground. I wanted to know if AI-assisted development could produce something that experienced developers would look at and say “yeah, I can work with this.” A game was the perfect stress test: complex state management, 3D rendering, economic simulation, NPC dialogue, and combat—all the things that expose architectural cracks fast.
The answer was yes, but only with serious discipline. Building Tramp Freighter is what taught me that AI needs pushback on your specs, alignment checks on your tasks, regular architecture reviews, and constant vigilance against degradation. Those four lessons became PAAD.
To see how far both AI and I have come, compare Tramp Freighter to an earlier AI experiment—a simple escape room game that now feels like a lifetime ago.
Play Tramp Freighter Blues | View the source code
Ananta
The standard approach to AI document search is RAG—Retrieval-Augmented Generation. It chops your documents into chunks, finds the ones that seem relevant, and feeds them to the AI. But RAG is inherently lossy: it discards context that didn’t match the query. It often needs careful tuning depending on what you’re analyzing. And if you take the simpler “just answer from these documents” approach, you can easily blow through context windows before the AI has seen enough to give a good answer.
Ananta takes a different approach: the AI reads your documents directly, writes code to search and cross-reference them, and keeps iterating until it’s confident. No context window limits, no lost information.
The result is deep, cross-document reasoning that standard approaches get wrong. In one demo, Ananta searched across seven novels, extracted thirty chronological events with supporting quotes, and spotted a continuity conflict between books—the kind of analysis that typically trips up AI.
Ananta works with text, code, PDFs, and Word documents. It supports ChatGPT, Claude, or Gemini APIs or you can run it locally with Ollama so nothing leaves your machine.
Point the Code Explorer at a GitHub repository and ask how authentication works—it’ll answer with file and line citations. Or have it load up multiple projects and ask it to build out an HLD (high-level diagram) of new work and get a rough draft in minutes instead of days of an architect’s time.
The approach is based on Recursive Language Models , a technique that gives AI effectively unlimited reading capacity.
PAAD
Everyone is focused on making AI coding “better.” But think about how we already build software with humans: we write tests, do code reviews, run CI/CD, have QA, run user acceptance testing, and still need ITSM to clean up the mess when bugs make it through. We don’t trust any single step—we apply defense in depth.
Why would we treat AI any differently?
PAAD is a Claude Code plugin that applies that same defense in depth to AI-assisted development. It encodes four disciplines that catch the ways AI silently goes wrong:
- Pushback—challenges your specs for omissions, ambiguities, and contradictions before a single line of code is written
- Alignment—verifies that implementation tasks match the spec exactly, catching the scope drift that AI introduces every time
- Architecture—dispatches five specialized agents to review your codebase’s structural integrity, because AI builds features without caring whether they fit together
- Discipline—the ongoing practices that prevent decay: test coverage, linting, formatting, and automated checks that catch what slips through everything else
Each discipline was born from a specific failure I hit while building these projects. Together, they’re the reason the code holds up.
PAAD was built for Claude Code but also works with Cursor, Kiro, and Antigravity, and should be easily portable to most AI coding tools that support skills.
![]()
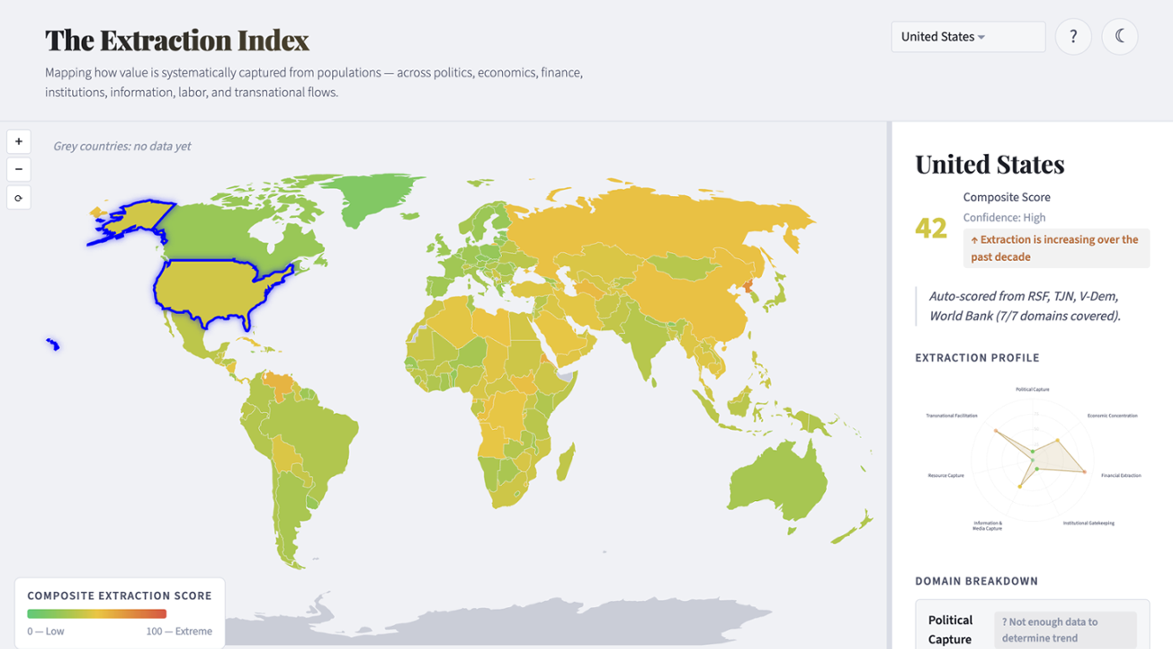
The Extraction Index
Most countries that top the corruption rankings aren’t where the real damage happens. A country can score well on every anti-corruption index and still extract massively through legal channels—financialized healthcare, wage stagnation despite rising productivity, a justice system that funnels billions from the poor. None of that registers as “corruption.” Almost all of it is perfectly legal.
The Extraction Index makes it visible. It’s an interactive world map that scores every country across seven domains—from political capture to financial secrecy to whether a country helps other countries extract from their own populations. Click a country, see where the extraction is concentrated, and adjust the weights yourself to reflect what matters most to you.